An assortment of links
At a surface level these piqued my interest, I’m storing them here to read later:
- https://medium.com/@montano_michael/digital-%C3%A6ther-ccd936aa996c
- https://www.rheingold.com/texts/tft/
- https://smallai.in/app/book-explorer/
-
NATURAL LANGUAGE, SEMANTIC ANALYSIS AND INTERACTIVE FICTION: https://worrydream.com/refs/Nelson_G_2006_-_Natural_Language,_Semantic_Analysis_and_Interactive_Fiction.pdf
-
Formality Considered Harmful: Experiences, Emerging Themes, and Directions on the Use of Formal Representations in Interactive Systems: https://link.springer.com/article/10.1023/A:1008716330212
-
Ossa: Towards the Next Generation Web: https://jamesparker.me/blog/post/2025/08/04/ossa-towards-the-next-generation-web
-
http://newforestcentre.info/uploads/7/5/7/2/7572906/koestler_the_ghost_in_the_machine.pdf
-
https://jack-vanlightly.com/blog/2025/6/11/coordinated-progress-part-1
-
https://www.wenger-trayner.com/introduction-to-communities-of-practice/
-
https://archive.org/details/logicdatabases0000symp/page/n5/mode/2up
-
https://untested.sonnet.io/notes/an-everything-canvas/ https://github.com/eejai42/conceptual-model-completeness-conjecture-toe-meta-model
-
- I intend to reach out to this person after I move, I like their writing a lot :)
-
https://web.archive.org/web/20211208055926/https://xeny.net/Muddle%20Your%20Way%20To%20Success
-
https://web.archive.org/web/20101212030638/http://anonyblog.com/archives/2004_07.html
-
https://maggieappleton.com/gathering-structures#start-small-and-simple
-
https://notes.andymatuschak.org/zCMhncA1iSE74MKKYQS5PBZ?stackedNotes=Maggie_Appleton
-
https://www.partykit.io/ & https://blog.partykit.io/posts/ai-interactions-with-tldraw
-
https://www.matthewsiu.com/pathfinder
-
-
this allows you to find a “path” between two words
-
[] todo: document my idea related to this for osintbuddy
-
[] todo: add edge expand hover effect to osintbuddy
-
-
- [] todo: see if I can take any ideas here for OSIB (osintbuddy)
-
https://dynamicland.org/archive/2013/Directions_for_lab_and_work
-
https://www.tandfonline.com/doi/full/10.1080/29974100.2025.2517191
-
https://news.ki.se/new-research-confirms-that-neurons-form-in-the-adult-brain
-
https://blog.redplanetlabs.com/2025/06/17/make-worse-software-slower/
-
https://www.scientificamerican.com/article/cells-can-hear-sounds-and-respond-genetically/
-
https://promptcoding.substack.com/p/theft-problem-in-open-source-code
- leave a reply or subscribe so I can invite you to a transparent and fair platform that I am launching in the coming months!
-
https://maalvika.substack.com/p/being-too-ambitious-is-a-clever-form
- There is a moment, just before creation begins, when the work exists in its most perfect form in your imagination. It lives in a crystalline space between intention and execution, where every word is precisely chosen, every brushstroke deliberate, every note inevitable, but only in your mind. In this prelapsarian state, the work is flawless because it is nothing: a ghost of pure potential that haunts the creator with its impossible beauty.
-
https://www.baldurbjarnason.com/2025/trusting-your-own-judgement-on-ai/
-
https://www.nature.com/articles/s41598-025-97370-z
-
This study shows that exposure to light that preferentially targets circadian photoreception reduces loss aversion, which may encourage gambling behaviour.
-
-
https://users.rust-lang.org/t/writing-a-plugin-system-in-rust/119980
-
https://www.canariproject.com/en/latest/canari.quickstart.html
-
https://blog.elest.io/browserless-free-open-source-website-scraping-automation-tool/
-
instant browser startup web scraping snapshots site:github.com
-
https://gist.github.com/paulproteus/356a6c008ec956ca29742e1b95997a61
- This document explains some risks of server-side image processing and explains a technique to make that much safer. I recommend using this technique.
-
https://gist.github.com/corporatepiyush/c30bfc78252da689a692c4db2035e3f0
- This script creates a true binary-compatible proxy that preserves all the binary interfaces of the original executable while adding nsjail sandboxing. This approach is more sophisticated than a simple wrapper, as it maintains full binary compatibility.
-
https://gist.github.com/cedrickchee/f729e848b52eab8fbc88a3910072198c
-
https://gist.github.com/jussker/e825980ed46af2b99318e19ef01083be
-
https://lcamtuf.substack.com/p/monkeys-typewriters-and-busy-beavers
-
https://addxorrol.blogspot.com/2025/07/a-non-anthropomorphized-view-of-llms.html
-
https://undark.org/2024/09/11/the-rise-of-the-science-sleuths/
-
https://contraptions.venkateshrao.com/p/be-history-or-do-history
-
https://www.sciencedaily.com/releases/2025/06/250610074301.htm
-
https://spanner.fyi/ (Spanner is a distributed database Google initiated a while ago to build a highly available and highly consistent database for its own workloads)
-
todo, check out this product eventually: https://sumble.com/orgs
-
WOAH, this is a brilliant idea: https://news.ycombinator.com/item?id=44498133
-
another cool-looking product I want to check out: https://www.secoda.co/blog/visualize-data-relationships-erds-secoda
-
https://josephthacker.com/ai/2025/07/07/the-real-future-of-tech.html
-
https://papersplease.org/wp/2025/07/08/the-dangers-of-identity-databases/
-
https://rmarcus.info/blog/2023/07/25/papers.html
- Most influential database papers
-
https://kruzenshtern.org/writings/2021-05-21-run-python-in-a-sandbox-with-nsjail
-
https://www.gladia.io/blog/best-open-source-speech-to-text-models
-
https://devdoc.net/web/developer.mozilla.org/en-US/docs/Mozilla/Add-ons/WebExtensions/Developing_WebExtensions_for_Firefox_for_Android.html - https://extensionworkshop.com/documentation/develop/developing-extensions-for-firefox-for-android/
-
- Infinity is not a big number
-
https://www.phoronix.com/news/Chromium-Skia-Graphite - Google Developing Skia “Graphite” For Faster Chrome: Multi-Threaded + Modern Graphics APIs
-
https://www.lexology.com/library/detail.aspx?g=bbef1939-2af0-465a-8b8f-c1ff3ebe9118
- The new EU Product Liability Directive: Implications for software, digital products, and cybersecurity
- The PLD explicitly includes software, AI, and digital services within the definition of “products” subject to strict liability.
- Non-compliance with cybersecurity requirements or failure to provide security updates can constitute a product defect.
- Companies cannot contractually exclude or limit their liability for software or cybersecurity defects.
- Increased litigation risk is expected because of expanded liability and collective redress mechanisms.
- The new EU Product Liability Directive: Implications for software, digital products, and cybersecurity
-
https://asteroid.ai/blog/graph-powered-browser-agents
- I should something like this for OSINTBuddy…
-
break complex tasks into simple, connected steps.
-
Each graph node handles a small, focused job—like “click search” or “fill out step 4 of the form”
-
https://www.wildbarethoughts.com/p/taste-is-the-new-intelligence
-
Taste is often dismissed as something shallow or subjective. But at its core, it’s a form of literacy—a way of reading the world. Good taste isn’t about being right. It’s about being attuned. To rhythm, to proportion, to vibe. It’s knowing when something is off, even if you can’t fully articulate why.
-
The people with taste aren’t always the loudest. They’re the ones whose work has resonance. Whose rooms feel calm. Whose recommendations always land. They have an internal tuning fork that rejects the cheap dopamine of novelty for something more enduring.
-
This isn’t just about design. It’s about thought. Taste is what allows you to skim past the performative noise, the fake depth, the viral bait, and know—instinctively—what’s worth your time.
-
-
https://www.grayolson.me/blog/posts/misunderstood-memory-ordering/
-
- Switchable multiple product UI, should add something like this to OSINTBuddy
-
https://www.noemamag.com/why-science-hasnt-solved-consciousness-yet/
-
https://www.templeton.org/grant/information-architectures-that-enable-life-the-emergence-of-meaning
-
https://your-commonbase.beehiiv.com/p/we-traded-fun-for-practicality
-
https://waysofdoing.rpp.works/notes/types-of-problem-start-small-do-it-for-real
-
https://academic.oup.com/nc/article/2024/1/niae039/7920510?login=false
-
https://memgraph.com/blog/five-recommendation-algorithms-no-recommendation-engine-is-whole-without
-
https://jmlr.csail.mit.edu/papers/volume13/lee12b/lee12b.pdf
-
https://dl.acm.org/doi/10.1145/3746174 - When Is WebAssembly Going to Get DOM Support?: Or, how I learned to stop worrying and love glue code
-
https://www.softwareheritage.org/2025/07/07/code-exhibit-unesco-cfp/
-
https://github.com/0x676e67/rnet
- TODO: Add to OSIB
-
https://charity.wtf/2025/07/09/thoughts-on-motivation-and-my-40-year-career/
-
https://www.henrypray.com/writings/the-only-saas-feature-you-should-be-building
-
https://www.raptitude.com/2025/04/doing-more-is-often-easier/
-
https://elevanth.org/blog/2025/07/09/which-kind-of-science-reform/
-
https://nicholasdecker.substack.com/p/can-we-believe-anything-about-markups
-
https://kevinlu.ai/the-only-important-technology-is-the-internet
-
https://link.springer.com/article/10.1007/s12200-025-00154-6
-
https://manualdousuario.net/en/revisiting-my-digital-security-model/
-
https://www.recall.ai/blog/postgres-listen-notify-does-not-scale
-
https://www.oreilly.com/openbook/opensources/book/raymond2.html
-
https://www.gap-map.org/capabilities/automated-scientific-fraud-detection/
- Develop AI and multimodal LLM systems to automatically detect fraudulent research, flag suspicious publications, and improve overall scientific integrity. Especially as rapid advancements in AI models make it feasible to generate inaccurate scientific content at scale to disrupt.
-
https://surfingcomplexity.blog/2025/06/01/pattern-machines-that-we-dont-understand/
-
https://jfmengels.net/essential-and-accidental-configuration/
-
https://medium.com/@plonska.ola_24342/no-code-tools-for-data-science-in-2025-607d41a3f610 - I want to make parts of making OSIB plugins no-code/low-code, maybe there’s some ideas I can take from here…
- Integrated AI Assistance — smart guidance. Modern tools need built-in AI agents that can explain results, generate workflows, and even teach concepts in real time.
- Full Data Science Workflow Support — from loading and cleaning data to modeling, evaluation, and reporting. No-code tools must cover the entire lifecycle, not just charts or dashboards.
- Model Transparency & Explainability — especially important in regulated industries or critical applications. Users need visual explanations, feature importance, and interpretable outputs — even without code.
- Offline & Secure Execution — privacy matters. Tools should allow local work with sensitive data, without requiring constant cloud access.
- Smooth Transition to Code — the best tools are no-code by default, but not code-locked. They should allow exporting workflows, reviewing code, or switching to script mode when needed.
- Collaboration & Reproducibility — In 2025, teams work together asynchronously. Tools must support shared workflows, versioning, and notebook-style exports. Support for AI & AutoML — manual feature engineering is out; smart automation is in. Users expect tools to suggest models, tune hyperparameters, and optimize pipelines, with just a few clicks. MLJAR Studio
Advantages: Built-in AI Agent (3 modes) — Code Assistant, Data Analyst, and Teacher — supports code generation, data insights, and interactive learning. Fully offline — ideal for working with sensitive data in enterprise and regulated environments. Code export — every step can be saved as clean Python code that is compatible with Jupyter Notebooks. AutoML included — MLJAR-supervised provides fast model training, a leaderboard, model interpretation, and detailed reports. Simple desktop installation — no manual setup of packages or environments. Ready to use code recipes — called Piece of code, sorted by categories. Works with all data types. Complete transparency — you always see what’s happening under the hood. Limitations: There are no built-in cloud collaboration features (but you can share the notebook as a web app or dashboard with Mercury). Desktop-only — not accessible from a browser.
KNIME
- Visual workflow builder — powerful drag-and-drop interface for building complex data pipelines.
- Extensive library of nodes — covers data prep, ML, NLP, database access, Python, R, Spark.
- Offline mode — works entirely on local machines.
- Strong integrations — supports external tools, scripting, and enterprise connectors. Limitations:
- Can be overwhelming for beginners — lots of configuration steps.
- Limited support for modern ML frameworks like transformers or LLMs.
- High memory usage on large workflows.Basic AI assistance is available via LLM extension (as of KNIME 5.2), but is limited in capabilities compared to native, notebook-integrated agents.
-
this is really interesting, I want to take some notes on bioelectricy: https://archive.ph/WXcSE
- https://www.liebertpub.com/doi/10.1089/bioe.2022.0012
-
What does seem to be key is that replication of life requires a structure that can, when ready, dissipate energy, but to grow and repair it also requires a polymer containing the instructions to build new bits, which perhaps suggests a key component of the definition life is that it can rebuild damaged components, enabling it to maintain dissipation over extended periods of time and robustness to adapt to variations in the environment.
-
https://forum.cloudron.io/topic/6079/photon-site-crawler-osint-tool
-
https://chromewebstore.google.com/detail/automa/infppggnoaenmfagbfknfkancpbljcca
- TODO: OSIB extension
-
https://www.uninformativ.de/blog/postings/2025-07-13/0/POSTING-en.html
-
https://forums.insertcredit.com/t/what-was-cyberpunk-in-memoriam-1980-2020/1721
-
- TODO: make a feed for osintbuddy like this, this is a very cool project
-
https://stratechery.com/2025/tech-philosophy-and-ai-opportunity/
-
https://www.sabrina.dev/p/ultimate-ai-coding-guide-claude-code
-
https://ozeanmedia.com/political-research/adventures-in-vibe-coding-with-ai-from-a-non-coder/
-
https://blog.thelifeofkenneth.com/2017/11/creating-autonomous-system-for-fun-and.html
-
https://martinfowler.com/articles/exploring-gen-ai/i-still-care-about-the-code.html
-
https://rogermartin.medium.com/going-on-the-offensive-with-creative-strategy-3310d9c1c2d6
-
https://learnerncoffee.wordpress.com/2025/07/08/you-cannot-make-everyone-happy/
-
https://writings.stephenwolfram.com/2012/03/the-personal-analytics-of-my-life/
-
https://engineeringideas.substack.com/p/trace-llm-workflows-at-your-apps
-
https://michaelbastos.com/blog/why-the-debt-vs-asset-metaphor-holds
-
https://www.anvilsecure.com/blog/scanning-for-post-quantum-cryptographic-support.html
-
https://jacobin.com/2025/07/knowledge-workers-ai-globalization-deindustrialization/
-
https://netwars.pelicancrossing.net/2025/07/04/second-sight/
-
https://www.notesfromthecircus.com/p/the-magical-thinking-thats-killing
-
https://www.uni-muenster.de/news/view.php?cmdid=14852&lang=en
-
https://spectrum.ieee.org/quantinuum-fault-tolerant-quantum-computing
-
https://holtze.me/2025/07/12/the-future-is-local-why-llms-should-run-on-your-own-machine/
-
https://waqaswrites.substack.com/p/demystifying-platform-product-management
-
https://www.theregister.com/2025/07/12/the_price_of_software_freedom/
-
https://worksonmymachine.substack.com/p/the-great-flood-of-adequate-software
-
https://phys.org/news/2025-07-multisynapse-optical-network-outperforms-digital.html
-
https://medicalxpress.com/news/2025-07-mathematical-reveals-humans-narrative-memories.html
-
https://www.hillelwayne.com/post/influential-dead-languages/
-
https://www.startingfromnix.com/p/uncertainty-is-an-evocative-state
-
https://www.businessinsider.com/gen-z-divide-how-graduation-year-impacts-hiring-outcomes-2025-7
-
https://qspace.fqxi.org/competitions/introduction#banner_menu_wrapper
-
https://unenumerated.blogspot.com/2012/07/pascals-scams.html
-
https://lemire.me/blog/2025/07/12/why-measuring-productivity-is-hard/
-
https://hbr.org/2025/07/why-understanding-ai-doesnt-necessarily-lead-people-to-embrace-it
-
https://medium.com/@sharvanath/software-3-0-vs-2-0-vs-1-0-5b1ab7670c9e
-
https://users.cs.utah.edu/~elb/folklore/mel-annotated/mel-annotated.html
-
https://www.argmin.net/p/are-developers-finally-out-of-a-job
-
https://medium.com/@adityb/gitwhisper-hackathon-build-5c5e448ddc16
-
https://www.metalabel.com/studio/release-strategies/how-culture-is-made
-
https://insurance-canada.ca/2023/06/29/skopenow-link-analysis-osint-investigations/
-
https://link.springer.com/article/10.1007/s11280-024-01297-w
-
https://ela.kpi.ua/items/c198a709-8bf9-4076-a070-ad77d4356b91
-
https://link.springer.com/chapter/10.1007/978-981-96-4506-0_22
-
https://www.tandfonline.com/doi/full/10.1080/09540091.2025.2518991
-
https://lambdaisland.com/blog/2025-07-03-on-cognitive-alignment
-
https://scienceblog.com/bee-flight-movements-hold-key-to-smarter-ai-systems/
-
https://gardnermcintyre.com/post/the-goal-is-to-think-as-little-as-possible
-
https://jessesingal.substack.com/p/a-chatbot-coined-a-phrase-i-really
-
https://blog.codingconfessions.com/p/one-law-to-rule-all-code-optimizations
-
https://isonomiaquarterly.com/archive/volume-3-issue-2/five-years-after/
-
https://theprogrammersparadox.blogspot.com/2025/07/assumptions.html
-
https://deepcausality.com/blog/towards-undamental-causality/
-
https://direct.mit.edu/qss/article/5/4/991/123928/Challenges-in-building-scholarly-knowledge-graphs
-
https://www.sciencedirect.com/science/article/pii/S0167923620300580
-
https://link.springer.com/article/10.1007/s10115-025-02414-5
-
https://link.springer.com/chapter/10.1007/978-3-031-94578-6_8
-
https://www.theinvestigator.blog/blog/osint-browser-extensions
-
https://graphaware.com/resources/automating-osint-data-collection-into-knowledge-graph-using-llms/
-
https://github.com/osintambition/Awesome-Browser-Extensions-for-OSINT
-
https://www.sciencedirect.com/science/article/abs/pii/S0950705124010190
-
https://link.springer.com/article/10.1007/s11227-021-04224-2
-
https://antmicro.com/blog/2024/03/introducing-jswasi-a-wasm-runtime-for-browsers/
-
https://digitalseams.com/blog/what-birdsong-and-backends-can-teach-us-about-magic
-
https://log.schemescape.com/posts/misc/my-hobby-is-bikeshedding.html
-
https://tratt.net/laurie/blog/2025/the_llm_for_software_yoyo.html
-
https://www.simpleanalytics.com/blog/google-is-tracking-you-even-when-you-use-duck-duck-go
-
https://issues.org/network-innovation-wellcome-leap-dugan-gabriel/
-
https://blog.logrocket.com/comparing-best-react-timeline-libraries/#react-timeline-libraries
-
https://jyn.dev/you-are-in-a-box/
- TODO: WAIT FOR HIS NEXT POST, IM HOOKED!
-
https://www.stranger.systems/posts/by-slug/row-polymorphic-programming.html
-
https://blog.logrocket.com/build-polymorphic-components-rust/
-
https://plainvanillaweb.com/blog/articles/2025-07-13-history-architecture/
-
https://www.smashingmagazine.com/2025/07/design-patterns-ai-interfaces/
-
https://3quarksdaily.com/3quarksdaily/2025/07/a-quantum-correspondence.html
-
https://pluralistic.net/2025/07/14/pole-star/#gnus-not-utilitarian
-
https://www.quantamagazine.org/rna-is-the-cells-emergency-alert-system-20250714/
-
https://best.openssf.org/CRA-Brief-Guide-for-OSS-Developers.html
-
https://www.cbsnews.com/news/cracking-the-code-using-genetic-genealogy-to-unmask-serial-criminals/ https://www.nature.com/articles/d41586-025-02233-2
-
https://www.raptitude.com/2025/05/the-truth-is-a-niche-interest-for-human-beings/
-
https://bencornia.com/blog/maximizing-leverage-in-software-systems
-
https://daniel.haxx.se/blog/2025/07/14/death-by-a-thousand-slops/
-
https://www.theregister.com/2025/07/14/software_rot_opinion/
-
https://www.digitaldigging.org/p/how-ai-bots-quietly-dismantle-paywalls
- Ill be really mad if archive sites get taken down >:(
-
https://the-nerve-blog.ghost.io/to-be-a-better-programmer-write-little-proofs-in-your-head/
-
https://www.evalapply.org/posts/poor-mans-time-oriented-data-system/index.html
-
https://blog.fjrevoredo.com/are-personas-even-doing-something-when-prompting/
-
https://tablbrowser.com/ - multiplayer browser?!
-
https://www.gojiberries.io/advertising-without-signal-whe-amazon-ads-confuse-more-than-they-clarify/
-
https://www.davidtinapple.com/illich/1983_silence_commons.html
- ”The Computer-Managed Society,” sounds an alarm. Clearly you foresee that machines which ape people are tending to encroach on every aspect of people’s lives, and that such machines force people to behave like machines. The new electronic devices do indeed have the power to force people to “communicate” with them and with each other on the terms of the machine. Whatever structurally does not fit the logic of machines is effectively filtered from a culture dominated by their use.
- The machine-like behaviour of people chained to electronics constitutes a degradation of their well-being and of their dignity which, for most people in the long run, becomes intolerable. Observations of the sickening effect of programmed environments show that people in them become indolent, impotent, narcissistic and apolitical. The political process breaks down, because people cease to be able to govern themselves; they demand to be managed.
- I congratulate Asahi Shimbun on its efforts to foster a new democratic consensus in Japan, by which your more than seven million readers become aware of the need to limit the encroachment of machines on the style of their own behaviour. It is important that precisely Japan initiate such action. Japan is looked upon as the capital of electronics; it would be marvellous if it became for the entire world the model of a new politics of self-limitation in the field of communication, which, in my opinion, is henceforth necessary if a people wants to remain self-governing.
- Electronic management as a political issue can be approached in several ways. I propose, at the beginning of this public consultation, to approach the issue as one of political ecology. Ecology, during the last ten years, has acquired a new meaning. It is still the name for a branch of professional biology, but the term now increasingly serves as the label under which a broad, politically organized general public analyzes and influences technical decisions. I want to focus on the new electronic management devices as a technical change of the human environment which, to be benign, must remain under political (and not exclusively expert) control. I have chosen this focus for my introduction, because I thus continue my conversation with those three Japanese colleagues to whom I owe what I know about your country - Professors Yoshikazu Sakamoto, Joshiro Tamanoi and Jun Ui.
-
https://thefrailestthing.com/2011/08/25/kranzbergs-six-laws-of-technology-a-metaphor-and-a-story/
-
https://www.washingtonpost.com/world/2025/07/17/russia-internet-censorship/
-
https://it-notes.dragas.net/2025/07/18/make-your-own-backup-system-part-1-strategy-before-scripts/
-
https://worksonmymachine.substack.com/p/nobody-knows-how-to-build-with-ai
- The Architecture Overview isn’t really architecture. It’s “what would I want to know if I had amnesia?”
- The Technical Considerations aren’t really instructions. They’re “what would frustrate me if we had to repeat it?”
- The Workflow Process isn’t really process. It’s “what patterns emerged that I don’t want to lose?”
- The Story Breakdown isn’t really planning. It’s “how do I make progress when everything resets?”
- Maybe that’s all any documentation is. Messages to future confused versions of ourselves.
-
https://distantprovince.by/posts/its-rude-to-show-ai-output-to-people/
-
https://josephg.com/blog/in-the-long-run-gpl-code-becomes-irrelevant/
-
https://www.wheresyoured.at/the-remarkable-incompetence-at-the-heart-of-tech/
-
https://mikeschinkel.com/2007/will-microsoft-meet-occupational-programmers-needs/
-
https://thinkingafterivanillich.net/community/open-discussion/history-of-scarcity/
-
https://collectiveactionintech.substack.com/p/the-case-for-sabotage
- At a time when the AI tools we develop and use are being built on the labor of exploited ghost workers in the Global South, when Google, Microsoft, and Amazon’s contracts with the IDF to provide cloud computing for automated missile- targeting in the genocide of Palestinians in Gaza, when the Department of Homeland Security is scraping social media to abduct students off of the street and detain scientists at the border, our position as workers who build these and similar tools becomes highlighted not by flashlights but floodlights.
-
https://workerorganizing.org/who-holds-the-power-in-your-workplace-8924/
-
https://every.to/working-overtime/i-tried-ai-coding-tools-now-i-want-to-learn-to-code
-
Twelve essays. Nineteen authors. One overarching goal: Present an array of possible futures that the AI revolution might produce.
-
https://hazelweakly.me/blog/stop-building-ai-tools-backwards/
-
https://www.persuasion.community/p/its-time-to-take-on-the-male-malaise
-
https://www.youtube.com/watch?v=3WpuN7IxwcA&list=RDYyHLl-EnOIU&index=26
-
https://chromewebstore.google.com/detail/retrace-extension/amplkfldacppobiogcnjipegoekcmimc
-
https://www.cs.utexas.edu/~eunsol/courses/data/bitter_lesson.pdf
-
https://chromewebstore.google.com/detail/axiom-browser-automation/cpgamigjcbffkaiciiepndmonbfdimbb
-
https://medium.com/rustaceans/a-plugin-system-for-rust-but-not-only-using-webassembly-26bb3d327c10
-
https://tech.utugit.fi/soft/tools/lectures/dtek0097/2022-en/declarative/index.html
-
https://pyquesthub.com/creating-a-dynamic-plugin-system-in-python
-
https://www.reddit.com/r/rust/comments/6v29z0/plugin_system_with_api/
-
https://engineering.fb.com/2013/06/25/core-infra/tao-the-power-of-the-graph/
-
https://garymarcus.substack.com/p/how-o3-and-grok-4-accidentally-vindicated
-
https://www.amirsharif.com/protecting-my-attention-at-the-dopamine-carnival
-
https://www.sciencedirect.com/science/article/abs/pii/S0893608023003398
-
https://dev.to/devleader/plugin-architecture-in-blazor-a-how-to-guide-4b4c
-
https://www.literally.dev/resources/marketing-to-developers-done-right
-
https://koshka.love/babel/alternatives-to-big-technology.html
-
https://beta.addons.florisboard.org/projects/krystal-void-24
-
https://duckduckgo.com/?q=feedback+loops+AND+web+crawling&t=fpas&ia=web
-
https://learn-anything.xyz/ - this is cool, collaborative learning environment, reminds me of https://en.wikipedia.org/wiki/Deschooling_Society
-
https://duckduckgo.com/?t=fpas&q=life+as+a+sustained+chemical+reaction&ia=web
-
https://aeon.co/essays/how-jazz-and-dolphins-can-help-explain-consciousness
-
https://www.asad.pw/charging-ahead-vs-moving-on-from-a-project/
-
https://duckduckgo.com/?q=vox+mirrors+ai+avatarsfor+legacyand+memory&t=fpas&ia=web
-
https://duckduckgo.com/?t=fpas&q=flowstate+ai+real+time+focus+optimizatjon&ia=web
-
https://duckduckgo.com/?t=fpas&q=gigchain+decntralized+workforce&ia=web
-
https://spectrum.ieee.org/ar-in-a-contact-lens-its-the-real-deal
-
https://medium.com/schemadesignstudio/shaping-the-future-of-ai-interfaces-f23882100aef
-
https://uxdesign.cc/ai-ux-design-for-intelligent-interfaces-bc966e96107d
-
https://verved.ai/blog/design-experts-critique-ai-interfaces
-
https://greydynamics.com/an-introduction-to-fifth-generation-warfare/
-
https://radicle.xyz/2025/07/23/using-radicle-ci-for-development
-
https://github.com/xsyncio/sierra-dev/blob/main/sierra/invoker.py
-
https://stackoverflow.com/questions/58609056/dynamic-class-level-type-hints-in-python
-
https://www.askvg.com/tip-how-to-copy-export-urls-of-all-opened-tabs-in-firefox/
-
https://drossbucket.com/2021/06/30/hacker-news-folk-wisdom-on-visual-programming/
-
https://www.crunchydata.com/blog/generating-json-directly-from-postgres
-
https://speculativeedu.eu/approaches-methods-and-tools-for-speculative-design/
-
https://github.com/speculativeedu/The-SpeculativeEdu-Online-Repository
-
ACAF3C260
-
https://www.oldmapsonline.org/en/history/regions#position=2.7559/54.36/-101.08
-
https://www.geoffreylitt.com/2025/07/27/enough-ai-copilots-we-need-ai-huds
-
https://rdi.berkeley.edu/frontier-ai-impact-on-cybersecurity/
-
https://archive.org/details/humaneinterfacen00rask/page/6/mode/1up
-
https://www.jneurosci.org/content/early/2025/07/09/JNEUROSCI.1646-24.2025
-
https://infobytes.guru/articles/getting-started-rust-rabbitmq.html
-
https://jvns.ca/blog/2021/01/23/firecracker—start-a-vm-in-less-than-a-second/
-
https://web.archive.org/web/20170607195200/https://minimaxir.com/2016/12/pwned-network/
-
https://hoverbear.org/blog/postgresql-hierarchical-structures/
-
amazing design, wow: https://neon.com/
-
https://news.ycombinator.com/item?id=38834780 - https://thisisimportant.net/posts/content-as-a-graph/
-
cool css color picker here:
-
https://motherduck.com/blog/json-log-analysis-duckdb-motherduck/
-
Curated examples using the Actix ecosystem.
serious work
-
We’ve been disappointed by how unambitious people are in this sense with Jupyter notebooks. They haven’t pushed the medium all that hard; there is no Citizen Kane of Jupyter notebooks. Indeed, we’re barely beyond the Lumière brothers. Examples like Norvig’s notebook are fine work, but seem disappointing when evaluated as leading examples of the medium.
-
Aspiring to canonicity, one fun project would be to take the most recent IPCC climate assessment report (perhaps starting with a small part), and develop a version which is executable. Instead of a report full of assertions and references, you’d have a live climate model – actually, many interrelated models – for people to explore. If it was good enough, people would teach classes from it; if it was really superb, not only would they teach classes from it, it could perhaps become the creative working environment for many climate scientists.
-
The understanding would be transferable. Even a user who has understood only a tiny part of the material could begin tinkering, building up an understanding based on play and exploration. It’s common to dismiss such an approach as leading to a toy understanding; we believe, on the contrary, that with well enough designed scaffolding it can lead to a deep understanding. Developed in enough depth, such an environment may even be used to explore novel research ideas. To our knowledge this kind of project has never been seriously pursued. But it’d be fun to try.
-
Tools for thought are (mostly) public goods, and as a result are undersupplied: That said, there are closely-related models of production which have succeeded (the games industry, Adobe, AutoDesk, Pixar). These models should be studied, emulated where possible, and used as inspiration to find more such models. → What practices would lead to tools for thought as transformative as Hindu-Arabic numerals? And in what ways does modern design practice and tech industry product practice fall short? To be successful, you need an insight-through-making loop to be operating at full throttle, combining the best of deep research culture with the best of Silicon Valley product culture.
-
Take emotion seriously: Historically, work on tools for thought has focused principally on cognition; much of the work has been stuck in Spock-space. But it should take emotion as seriously as the best musicians, movie directors, and video game designers. Mnemonic video is a promising vehicle for such explorations, possibly combining both deep emotional connection with the detailed intellectual mastery the mnemonic medium aspires toward.
-
Tools for thought must be developed in tandem with deep, original creative work: Much work on tools for thought focuses on toy problems and toy environments. This is useful when prototyping, but to be successful such tools must ultimately be used to do serious, original creative work. That’s a baseline litmus test for whether the tools are genuinely working, or merely telling a good story. Ideally, for any such tool there will be a stream of canonical media expanding the form, and entering the consciousness of other creators.
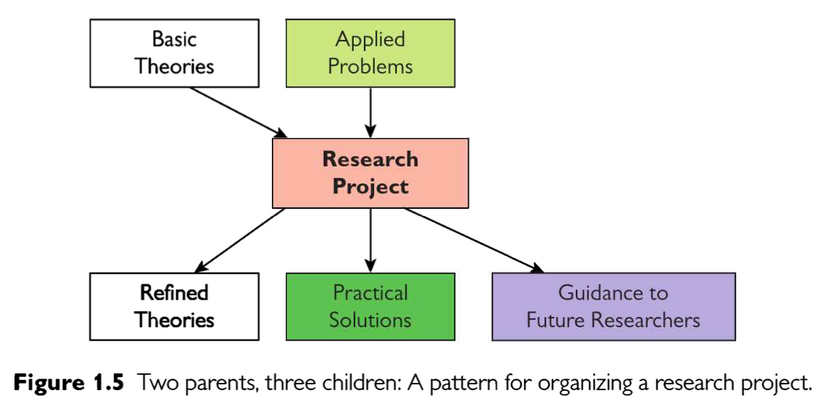
Ben Shneiderman, a pioneering human-computer interaction researcher, offers this charming schematic for research project design in The New ABCs of Research. He calls it the “two parents, three children” pattern.
The challenge is similar to what learning scientists must do in designing educational interventions. In Principles and Methods of Development Research, Jan van den Akker offers a beautiful distillation of what a unit of progress looks like in that field (thanks to Sarah Lim for the pointer):
[Educational design] principles are usually heuristic statements of a format such as: “If you want to design intervention X (for the purpose/function Y in context Z), then you are best advised to give that intervention the characteristics A, B, and C (substantive emphasis), and to do that via procedures K, L, and M (procedural emphasis), because of arguments P, Q, and R [(theoretical emphasis)].”
The key thing it does is to explicitly connect the dots between a grounded theoretical claim, the implied design approach, and the desired outcome. I’m certainly wary of trying to fit all research into some kind of formula like this, but how clarifying it is to have this target painted so sharply! If you’re a researcher and you want to develop some new intervention, you need to design an experiment whose results can generate a statement of this kind.
When I read your question about people completing “full cycles” of work I have a strong intuition that we should look for the names of institutions or perhaps loose movements rather than individuals. The mix of skills required are too broad even for most polymaths. And if I look at whole “scene” of tools for thought with a focus on people doing 1, 2, and 3, which is a very loose movement, I see just what you point out: a missing component for a working ratchet is the distillation of insights and critical reflection. I suspect this requires more than publication; what’s needed is some degree of interpersonal connection and mutual dependence. I see a very slow but productive ratcheting in the Quantified Self community, which unites academic researchers, (a few) clinicians and allied health professionals, and technologists of various types around supporting self-research, with the most active developers focusing their work around their own self-research projects while sharing tools, methods, and critical support. That’s the positive example: a scene that jelled. BUT, on the other hand, the resources associated with commercialization of self-tracking remain deeply siloed in consumer tech companies. The potential insights from the hundreds of millions of users of the commercial tools do not feed back very efficiently into the development of high level insights and new theories. In fact, the theoretical material about “behavior change” referenced by these companies is so outdated that I often doubt it carries much real weight in their internal research road map. It’s more window dressing than motivating theory. All of that said, I do think the development of Quantified Self and personal science offers an example with features worth imitating. Specifically:
- articulating a very high level common theoretical and/or cultural position can bring participants into contact based on the promise and challenge of realizing these rather abstract but important goals. (For us: “the right to participate in science” “individual discovery as a meaningful contribution to knowledge even in the absence of generalizability” “personal agency in determining one’s own research question and in control of data”)
- a common protocol/ritual for sharing knowledge (For us: First person point of view, and answering the three “prime questions”: what did you do, how did you do it, what did you learn.) These high level agreements and common structures create a scaffold for the different kinds of participants to begin to make their own contributions. As evidence, here’s a recent paper that attempts to theorize some self-research practice. It is based on the researchers own surveys, prototypes, and pilots, but it is deeply informed by their engagement with the wider community. It sticks to its lane (at least explicitly) in offering an academic contribution, but the implications will be clear to others “on the scene” wondering how to make their tools more effective: https://www.frontiersin.org/articles/10.3389/fdgth.2020.00003/full.
Gary Bernhardt / Execute Program seems like a decent example, as does Julia Evans / WizardZines.
Not all of the ideas explored in their work are fully articulated, generalized, and published, so some of it gets lost in tweets. But, ExecuteProgram has an internal representation of the conceptual dependencies between lessons. WizardZines is also not producing strictly generalizable academic insights, but a lot of the practical tools-for-making and how-to-think-about-making are reflected. in the blog, e.g. https://jvns.ca/blog/2020/06/14/questions-to-help-you-learn/
Both seem like they have the full cycle going - make tools (for learning, not for thought exactly), publish them, observe their use, distill insights, share.
-
https://alexharri.medium.com/the-engineering-behind-figmas-vector-networks-688568e37110
-
https://supermemo.guru/wiki/How_much_knowledge_can_human_brain_hold
-
https://numinous.productions/ttft/#exploring-tools-for-thought
-
https://plato.stanford.edu/entries/feminism-ethics/#EthiCareFemiGendApprMora
-
https://worrydream.com/refs/Kay_1989_-_User_Interface,_a_Personal_View.pdf
-
https://worrydream.com/refs/Hestenes_2002_-_Reforming_the_Mathematical_Language_of_Physics.pdf
-
https://dubfuture.blogspot.com/2009/11/i-give-up-on-chiuist.html
-
https://huggingface.co/spaces/hesamation/primer-llm-embedding?section=embeddings_in_modern_llms
-
https://stackoverflow.com/questions/26354465/creating-a-simple-rust-daemon-that-listens-to-a-port
-
https://hadid.dev/posts/github-trends/ - yay, finally someone did this :)
-
https://blogs.cisco.com/security/detecting-exposed-llm-servers-shodan-case-study-on-ollama
I started auto archiving all the URLs I visit to the wayback machine today. Hopefully this will help with link rot…
-
https://blog.ctms.me/posts/2024-08-29-running-this-blog-on-a-pixel-5/
-
https://infrequently.org/2025/09/apples-crimes-against-the-internet-community/
-
https://medium.com/@igor.atakhanov/your-mind-as-a-coalition-of-social-viruses-e423e92ba07a
-
https://harvest.aps.org/v2/journals/articles/10.1103/PhysRevE.93.032315/fulltext
-
https://paste.sr.ht/~awal/2310cfca431e9f723df281d02558eaebd77e2091
-
https://climatedrift.substack.com/p/its-time-for-you-to-contribute-to
-
https://www.colorado.edu/today/2025/08/28/new-ai-tool-identifies-1000-questionable-scientific-journals - TODO: review this literature and learn how to integrate such capabilities into osintbuddy
-
https://philpapers.org/rec/VENFTO - Formal theory of thinking - The definition of thinking in general form is given. The constructive logic of thinking is formulated. An algorithm capable of arbitrarily complex thinking is built.
-
https://utcc.utoronto.ca/~cks/space/blog/tech/PeopleCannotPickGoodSoftware
-
https://www.infoq.com/articles/federated-credentials-management-w3c-proposal/
-
https://www.cnn.com/2025/09/09/science/brain-map-decision-making
-
https://antifold.com/posts/topology-inspired-visualisation-article.html
-
https://80yos.substack.com/p/confessions-of-a-perpetual-beginner
-
https://dnsk.work/blog/why-i-only-design-mobile-apps-for-one-type-of-client-now/
-
https://blog.platformatic.dev/renewing-our-open-source-pledge-for-2025
-
https://www.betonit.ai/p/solving-the-mind-body-problem-dualism
-
https://news.slashdot.org/story/25/10/04/0648215/what-would-happen-if-an-ai-bubble-burst
-
https://toscalix.com/2025/10/07/open-source-communities-are-outstanding-learning-environments/
-
https://blog.demofox.org/2025/10/05/using-information-entropy-to-make-choices-choose-experiments/
-
https://arstechnica.com/science/2025/10/the-neurons-that-let-us-see-what-isnt-there/
-
https://buttondown.com/ashsmash/archive/your-creativity-is-benevolent-and-you-can-always/
-
https://sphericalcowconsulting.com/2025/10/07/the-end-of-the-global-internet/
-
https://restofworld.org/2025/latin-america-judges-ai-crimes/
-
https://www.exaequos.com/blog_wasm_wasi_compilers_in_exaequos.html
-
https://blog.genesmindsmachines.com/p/we-still-cant-predict-much-of-anything
-
https://www.schneier.com/essays/archives/2009/07/technology_shouldnt.html
-
https://unherd.com/2025/10/the-lefts-ugly-free-speech-fetish/
-
https://cased.com/blog/2025-10-07-you-can-just-open-source-things
-
https://static.googleusercontent.com/media/research.google.com/en//people/jeff/WSDM09-keynote.pdf
-
https://johnwdanner.medium.com/microschools-are-the-hacker-fringe-of-education-5a1b5bf980ef
-
https://paulkrugman.substack.com/p/why-arent-we-partying-like-its-1999
-
https://github.com/johnperry-math/AoC2023/blob/master/More_Detailed_Comparison.md
-
https://newsletter.pragmaticengineer.com/p/state-of-the-tech-market-in-2025-hiring-managers
-
https://www.startastory.app/blog/why-you-cant-write-your-own-founders-story/
-
https://karboosx.net/post/PJOveGVa/become-unbannable-from-your-emailgmail
-
https://www.allthingsdistributed.com/2025/10/better-with-age.html
-
https://en.wikipedia.org/wiki/Conflict-driven_clause_learning
-
https://www.ams.org/journals/bull/1976-82-01/S0002-9904-1976-13928-6/home.html
-
https://www.theolouvel.com/fieldnotes/Notions/Zeigarnik+Effect
-
https://www.biorxiv.org/content/10.1101/2025.10.03.680235v1?rss=1
-
https://direct.mit.edu/books/book/2005/I-of-the-VortexFrom-Neurons-to-Self
-
https://www.novaspivack.com/science/introducing-lace-a-new-kind-of-cellular-automata
-
https://paragraph.com/@protocolized/a-million-ways-to-die-in-the-web
-
https://paragraph.com/@protocolized/toward-enlightened-protocolism
-
https://paragraph.com/@protocolized/explorations-in-dynamic-range
-
https://paragraph.com/@protocolized/protocol-worlds-ii-holographic-cities
-
https://paragraph.com/@protocolized/disruptive-standards-making-and-re-move-a-graphic-novel
-
medium.com/ethereum-optimism/retroactive-public-goods-funding-33c9b7d00f0c
-
https://www.ribbonfarm.com/2014/05/08/science-and-other-off-the-wall-etudes
-
https://www.ribbonfarm.com/2011/08/26/the-scientific-sensibility/
-
https://paragraph.com/@protocolized/protocols-as-first-class-concepts
-
https://protocolized.summerofprotocols.com/p/sop-2025-accelerating-order
-
https://protocolized.summerofprotocols.com/p/tension-landscapes
-
https://protocolized.summerofprotocols.com/p/risky-autonomy-vs-walled-gardens
-
https://protocolized.summerofprotocols.com/p/consensus-nightmares
-
https://protocolized.summerofprotocols.com/p/the-last-archive
-
https://protocolized.summerofprotocols.com/p/mechanical-currents
-
https://protocolized.summerofprotocols.com/p/what-is-formal-protocol-theory
-
https://protocolized.summerofprotocols.com/p/a-very-short-introduction-to-memory
-
https://protocolized.summerofprotocols.com/p/the-house-that-paid-its-own-bills
-
https://protocolized.summerofprotocols.com/p/reflections-from-memoria
-
https://protocolized.summerofprotocols.com/p/risky-autonomy-vs-walled-gardens
MUST READ!
https://summerofprotocols.com/research
https://summerofprotocols.com/
-
https://www.sciencedirect.com/journal/business-horizons/vol/60/issue/6
-
https://www.sciencedirect.com/science/article/abs/pii/S0007681317300988
-
https://cio-wiki.org/wiki/Gartner%27s_PACE_Layered_Application_Strategy
-
https://medium.com/@komorama/the-magic-of-acorns-a3c91204d5f9
-
https://medium.com/@komorama/the-sarumans-and-the-radagasts-6392f889d142
https://www.k-a.in/mHC.html https://link.springer.com/article/10.1007/s12136-024-00584-5 https://biologyinsights.com/significant-gene-drug-interaction-impact-on-patient-care/ https://direct.mit.edu/opmi/article/doi/10.1162/opmi_a_00094/117074/The-Hard-Problem-of-Consciousness-Arises-from